| KanjiQuick Voice Documentation |
| [ Home Page | Downloads | Registration ] |
|
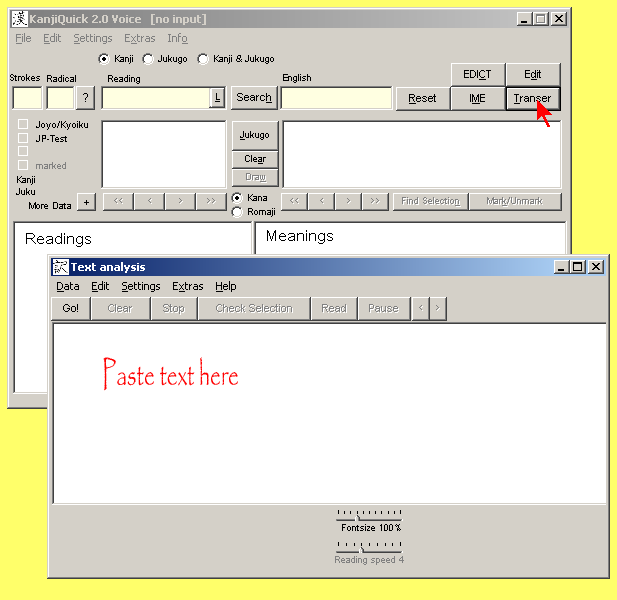
[ Contents ] Text Analysis using the Transer moduleKanjiQuick will analyze any Japanese text in the Text input box of the Transer Text Analysis module. The analysis will scan for words written in kanji (single or compound) and then search the database for the matching lexical entries. The proportion of kanji characters in a modern Japanese text, such as a newspaper, is usually between 30 to 40 percent. However, the kanji seem to be the difficult part when reading Japanese, while most of the words written in kana can easily be found in a Japanese-English dictionary, or may already be known to the user. (If not, try Jim Breen's EDICT database using EDICT Reader Japanese-English Dictionary.) First, click the button.
Paste in your text into the text input box that appears, and click
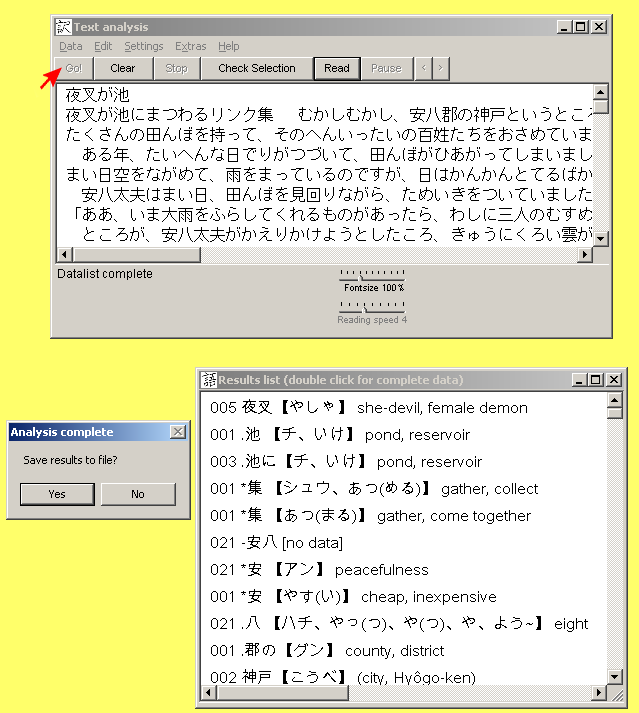
Since KanjiQuick cannot perform complex semantic analyses, it will simply scan any kanji string in the Text input box for database matches. In some cases the KanjiQuick analysis may fail. For example, if the kanji string contains prefixes and/or suffixes comprised of a single kanji, or if it contains person or place names with special readings. If no match is found in the database for the combination of characters, the information in the Results List will read [no data] beside the unknown entry. You still may be able to locate a single kanji and its readings and meanings by clicking on it, and using KanjiQuick's main program window . All entries in the list are placed in order of their occurrence in the text. However, items already in the list will not be duplicated with subsequent occurrences. A frequency counter to the left of each entry will inform you how many times a kanji or compound has appeared in the text. For additional information about starting Transer and memory management, click here. Voice GenerationAs an option, KanjiQuick can be provided with a text reader which will allow you to have any Japanese text in the Text input box read by voice. For details, click here. |
| [ Contents ] |
menu items, sliders | | Text input boxes | | display boxes | | separate windows | ||
|
Copyright © Program coding and design by Kay Genenz on behalf of JaF, Duesseldorf, Germany 2002. |